Back Propagation
역전파(back propagation) 알고리즘은 효과적으로 각 변수의 함수값에 대한 미분값(기울기)을 구하는 알고리즘입니다. 더 정확한 이름은 역방향의 오차 전파(backward error propagation)입니다. 즉, 역방향, 오차 ,전파 3가지를 알면 역전파 알고리즘을 이해할 수 있습니다. 역방향의 반대는 정방향(forward) 입니다. 우리가 만든 그래프의 엣지 방향대로 계산해 나가는 것을 정방향 전파, 엣지를 거슬러 올라오는 것이 역방향 전파라고 생각할 수 있습니다. 역전파 알고리즘이 훈련 알고리즘이라고 착각할 수 있는데, 역전파 알고리즘은 그저 기울기만을 계산해 줄 뿐 SGD 와 같은 훈련 알고리즘과는 다른 내용입니다. Theano와 Tensorflow같은 패키지들이 자동 미분(auto differentiation)을 지원하면서 역전파 알고리즘을 어떻게 구현해야 하는지에 대한 고민은 거의 없어졌습니다. 그럼에도 불구하고, 역전파 알고리즘을 구현하는 방법을 알고 있는 것은 여전히 중요합니다.
- Backward propagation - 훈련에 사용한다.
- Forward propagation - 추론(inference)에 사용한다.
Chain Rule
연쇄 법칙(chain rule)은 여러 개의 합성된 함수에서 변수에 대한 미분을 구하는 방법입니다. 연쇄 법칙 덕분에 미분값을 구하는 것은 출력에 대한 입력의 미분값을 구하고 계속 더하거나 곱해주는 과정으로 간략화됩니다. 가장 간단한 예제는 다음과 같습니다. 우선 \(z\)는 스칼라 값이라고 생각하겠습니다. 실제로도 인공신경망 훈련 과정에서 훈련에 대한 점수는 손실 함수(loss)에서 나온 스칼라 값으로 주어집니다.
위 식에서는 두 개의 노드가 등장합니다. \(x, y \in \mathbb{R} \) 이라고 생각할 때, \(\frac{dz}{dx}\)는 다음과 같이 구할 수 있습니다. 즉, 두 개의 노드를 각각 출력에서 입력으로 거슬러 올라오게 됩니다.
만약 \(x\in \mathbb{R}^m, y \in \mathbb{R}^n \)이라면 어떨까요?
위 식은 \(i\)가 고정된 상태에서는 두 벡터의 내적이라고 생각할 수 있고, \(i\)를 변경시키며 모든 \(x_i\)에 대해 계산한다면 결국 행렬-벡터 곱(matrix-vector multiplication)이 됩니다. 이는 아래 식과 같이 Jacobian 행렬로 표현할 수 있습니다.
Theano와 Tensorflow에서는 그래프를 기반으로 한 역전파 알고리즘을 사용합니다. 이 경우 기울기들은 그래프가 사용하는 입력들만을 사용해서 최종적으로 표현됩니다. 기울기를 구하는 그래프는 원래 그래프와 완전히 다른 새로운 그래프로 그려지는 것이 아니라, 기존 그래프에서 가지가 추가로 뻗어나와 계산되는 형태가 됩니다. 아래에 있는 기울기를 구하기 위해서는 위에 있는 기울기를 구해야 하고, 기울기를 구하는 과정에서 정방향 전파 때 계산했던 값들이 필요하게 됩니다. 이 과정은 거꾸로 거슬러 올라가는 것과 같은 형태가 되기 때문에 역전파 알고리즘이라고 합니다.
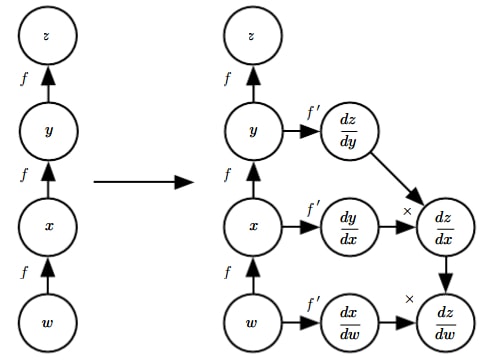
다음과 같은 식을 생각해 봅시다. 이 때 입력에 대한 출력의 기울기를 구하는 방법은 여러 가지가 있습니다. 노드 \(f\)에는 역방향 계산에 사용할 수 있는 \(f'\)도 같이 그림자처럼 존재합니다.
만약 정방향 전파 때 \(w,y\)를 계산한 값을 가지고 있었다면 위의 식이 더 계산하기 편리한 식입니다. 하지만 메모리가 부족한 (일반적인) 경우, 아래 식처럼 구현되고 계산됩니다. 아래 식의 장점은 오직 입력(들)만으로 모든 기울기를 나타낼 수 있다는 점입니다.
Error Propagation
역방향에 대해 알았으니, 이제 오차(error)를 다룹니다. 흔히 정방향 전파에서는 신호(signal)가 이동하고, 역방향 전파에서는 오차(error)가 이동한다고 이야기합니다. 오차란, 구하고자 하는 스칼라 값에 대한 신호의 기울기(미분값)를 의미합니다. 그리고 우리가 변수를 업데이트하기 위해 필요한 기울기는 스칼라 값에 대한 변수의 기울기(미분값)입니다. 다음과 같은 식을 생각해 보겠습니다.
\(\frac{dz}{dw}, \frac{dz}{db}, \frac{dz}{dx}\)를 구하기 위해서는 우선 \(\frac{dz}{dy}\) 를 구합니다. 여기서 변수는 \(w, b\)라는 것을 생각하면 \(\frac{dz}{dy}\)는 오차가 됩니다. \(f\)의 역방향을 통해 오차가 우선 전파되었습니다. 이제 \(+\)의 역방향을 통해 오차를 전파합니다.
위의 식은 그대로 변수 \(b\)의 기울기가 됩니다. 한편, 아래의 식은 아직 변수까지 가지 않았고 오차가 되었습니다. 이제 이 오차를 다시 \(\times\)의 역방향을 통해 전파합니다.
여기서, 역방향 함수뿐만 아니라 정방향에서 계산한 값 \(c, w\)도 중요하다는 것을 확인할 수 있습니다. 다시 위의 식은 변수 \(w\)의 기울기가 되었고, 아래의 식은 아직도 오차입니다. 이제 이 오차를 다시 \(g\)의 역방향으로 전파합니다.
노드 하나하나씩을 거슬러 올라가며 오차 전파를 해 보았습니다. 이 과정에서, 앞에서 구한 오차뿐만 아니라 정방향 전파에서 구한 신호의 값도 사용한다는 것을 알 수 있습니다.
Useful Gradients
인공신경망을 다루다 보면 몇몇 함수들을 미분한 결과를 알고 있으면 좋은 일들이 많이 생깁니다. 기울기를 생각하는 것은 인공신경망의 훈련과 관련해 직관(intuition)을 줍니다. 여기서는 많이 사용되는 4가지 함수, sigmoid, softmax, binary cross entropy, categorical cross entropy 를 미분해 봅니다.
Sigmoid Gradient
Sigmoid 함수는 다음과 같습니다. 보통 \(\sigma\) 기호로 표현하기도 합니다.
이를 미분하면 다음과 같습니다.
Sigmoid 함수가 널리 사용된 이유에는 미분이 간편하다(별도의 미분 식이 필요 없다)는 점도 있습니다. 기울기 식에서 확인할 수 있듯이 \(\sigma(x)\)가 0이나 1에 가까워질수록 기울기의 크기는 0이 되어 제대로 훈련이 안 되게 됩니다.
Softmax Gradient
Softmax 함수는 다음과 같습니다.
Softmax 함수가 골치아픈 이유는 \(x_i\)에 관여하는 항이 \(y_1, y_2 ... y_N\) 전체에 있다는 점입니다. 우선 쉬운 경우(\(j \neq k \))부터 해 볼 수 있습니다.
이제 어려운 경우를 해 봅니다.
Binary Cross Entropy
BCE 함수는 다음과 같습니다. 정답을 \(t\), 예측을 \(y\)라고 하겠습니다. 정답은 0 or 1인 이진 분류 문제입니다. 따라서 \(y\)는 0에서 1 사이의 값으로 나옵니다. \(L\) 에는 두 개의 항이 있지만 정답에 따라 한쪽 항만 살아남습니다.
미분하면 다음과 같습니다.
정답이 0이라면 기울기가 양수가 됩니다. 즉 \(y\)가 줄어드는 방향으로 훈련됩니다. 한편, 정답이 1이라면 기울기가 음수가 되고, \(y\)가 증가하는 방향으로 훈련됩니다. 정답에 가까워지는 것을 알 수 있죠!
Categorical Cross Entropy
CCE 함수는 다음과 같습니다. 마찬가지로 정답을 \(t\), 예측을 \(y\)로 하지만 둘 다 \(C\)개 클래스에 대한 답을 갖고 있는, 합이 1인 벡터입니다. \(t\)는 정답인 특정 클래스에서는 1, 다른 클래스에서는 0인 one-hot 인코딩된 벡터입니다.
미분하면 다음과 같습니다.
이 기울기는 많은 것을 말해 줍니다. 정답이 아니라면 기울기는 0입니다. 정답이라면 기울기는 \(-1/y_i\) 입니다. 즉, CCE 로 훈련하는 것은 정답인 쪽을 더 정답에 가깝도록 끌어올리는 것입니다. 정답이 아닌 경우에 대한 역전파는 없습니다. 이 때문에, CCE로 훈련하는 경우 정답에 대한 확신도 높지만 오답에 대한 확신도 과하게 높은 현상이 발생하곤 합니다.